Rodin Handbook
This work is sponsored by the Deploy Project
This work is sponsored by the ADVANCE Project
This work is licensed under a Creative Commons Attribution 3.0 Unported License
| Rodin User’s Handbook v.2.8 |
2.5.4 Introducing user-defined types
We can introduce our own new types simply by giving such types a name. This is done by adding the name of the type to the SETS section of a context. We will see how this is done in practice in the next section (2.6).
For instance, if we want to model different kind of fruits in our model, we might create the set  . Then the identifier denotes the set of all elements of this type. Nothing more is known about unless we add further axioms. In particular, we do not know the cardinality (number of elements) of the set or even if it is finite.
. Then the identifier denotes the set of all elements of this type. Nothing more is known about unless we add further axioms. In particular, we do not know the cardinality (number of elements) of the set or even if it is finite.
![\includegraphics[width=7mm]{img/warning_64.png}](images/img-0004.png)
Assume that we want to model
and
which are sub-sets of
and
with
and
. Then we cannot compare
or
. That would raise a type error because
and
expect the same type for the left and right expression.
If we want to model sub-sets and as described above, we can add them as constants and state that 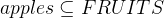 and
and 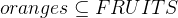 . If apples and oranges are all fruits we want to model, we can assume
. If apples and oranges are all fruits we want to model, we can assume 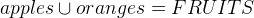 and if no fruit is both an apple and orange we can write
and if no fruit is both an apple and orange we can write 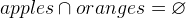 . A shorter way to express this is to say that apples and oranges constitute a partition of the fruits:
. A shorter way to express this is to say that apples and oranges constitute a partition of the fruits: 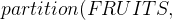
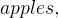
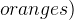 . In general, we can use the partition operator to express that a set
. In general, we can use the partition operator to express that a set 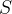 is partitioned by the sets
is partitioned by the sets  with
with 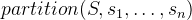 . We use partitions in Section 2.6.2.1.
. We use partitions in Section 2.6.2.1.
Another typical usage for user defined data types are enumerated sets. These are sets where we know all the elements already. Let’s take a system which can be either working or broken. We model this by introducing a type 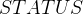 in the SETS section and two constants
in the SETS section and two constants 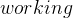 and
and 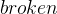 . We define that STATUS consists of exactly and by
. We define that STATUS consists of exactly and by 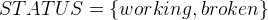 . Additionally, we have to say that and are not the same by
. Additionally, we have to say that and are not the same by 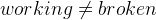 .
.
If the enumerated sets gets larger, we need to state for every two element of the set that they are distinct. Thus, for a set of 10 constants, we’ll need 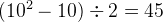 predicates. Again, we can use the partition operator to express this in a more concise way:
predicates. Again, we can use the partition operator to express this in a more concise way:
![\[ partition(STATUS,\{ working\} ,\{ broken\} ) \]](images/img-0139.png) |